
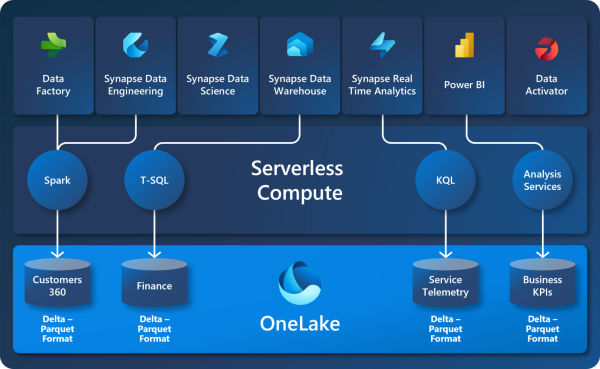
Many organizations have long depended on on-premise databases built on relational systems to manage their data. These setups have been crucial for structured data handling and analysis, offering stability and reliability. However, as data demands increase both in volume and complexity, more scalable, efficient, and cost-effective solutions are needed.
This is where technologies like Parquet and Delta Lake come into play. Parquet is a columnar storage format designed for efficient storage and quick query performance, perfect for large datasets that can overwhelm traditional databases. Delta Lake enhances Parquet by adding a robust transactional storage layer, ensuring data integrity with ACID compliance in cloud environments. Transitioning to these technologies not only shifts the storage mechanisms but also significantly improves data accessibility and management at scale.
The Role of Parquet in Microsoft Fabric
Parquet, a columnar storage file format, is designed to bring efficiency both in terms of storage and query performance. It is particularly effective for cloud environments where cost and speed are often critical considerations. By integrating Parquet, Microsoft Fabric allows applications to store data in a format that is optimized for large-scale analytics workloads, significantly reducing the I/O overhead and facilitating faster data retrieval, which is crucial for real-time data processing applications.
Key features of Parquet include:
- Columnar Storage: Instead of storing data row by row, Parquet stores it column by column, which allows for more efficient compression and encoding of data.
- Performance: Queries that need to read specific columns of the data can read only the required pieces, significantly reducing the I/O overhead and speeding up data retrieval.
- Compatibility: Parquet supports complex nested data structures and is compatible with a variety of data processing tools, making it a versatile choice for big data scenarios.
Advantages of Delta Parquet in Microsoft Fabric
Delta Parquet, or simply Delta Lake, extends the capabilities of traditional Parquet by providing a transactional storage layer that ensures ACID properties. This integration brings several key advantages to Microsoft Fabric:
- ACID Transactions: Ensures that all operations are atomic, consistent, isolated, and durable.
- Scalable Metadata Handling: Delta Lake can handle petabytes of data and billions of files without performance bottlenecks.
- Schema Enforcement: Automatically handles schema validation, which is critical when dealing with large-scale data ingestion from various sources.
- Time Travel: Users can access previous versions of the data for audits or rollbacks, an essential feature for debugging and compliance.
Use Cases in the Real World
- Real-Time Data Processing: Financial services can process and analyze transactions in real time, ensuring high throughput and low latency data feeds.
- Machine Learning: Data scientists can manage and version massive datasets more effectively, streamlining the development of machine learning models.
- E-commerce: Retailers can handle large volumes of customer data, improving personalization and customer service through faster data access and analysis.
Last but not the least, parquet and delta are closed related in many ways but they are different in the following aspects:
- Base Technology: Parquet is a file format, whereas Delta Lake is a storage layer that uses Parquet as its underlying storage format.
- Data Integrity and Transactions: Parquet alone does not support transactions. Delta Lake provides transactional capability with ACID properties to ensure data integrity across multiple operations.
- Use Case: Parquet is suitable for efficient data storage and quick query performance. Delta Lake is ideal for managing larger-scale, complex data environments where data integrity, versioning, and robust metadata management are required.
Essentially, Delta Lake extends the capabilities of Parquet by addressing some of the limitations around transaction management and data integrity that arise in large and complex data environments, making it more suitable for enterprise-level data workflows.