

In this post, I’ll explain how to add the current date and time to an existing PySpark DataFrame in a Fabric Notebook. This is particularly helpful when inserting data into a Fabric Lakehouse table, as it allows you to track when each record was added. I’ll walk through an example using a DataFrame to first load some sample data and show how to append a new column with the current timestamp to capture the insertion time.
The data I am using is new york taxi dataset, after I opened my notebook and attached my lakehouse, I can simply upload the file to my lakehouse.
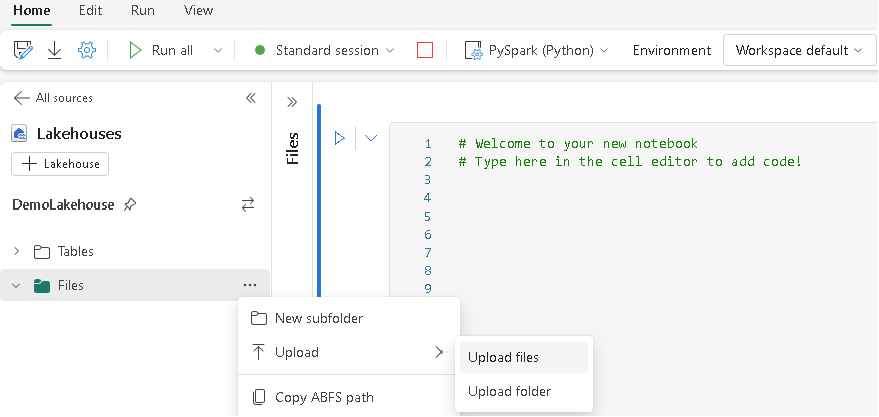
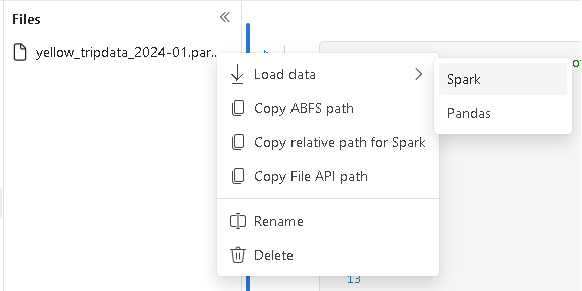
Once I confirm file being uploaded, I can load the data using spark.
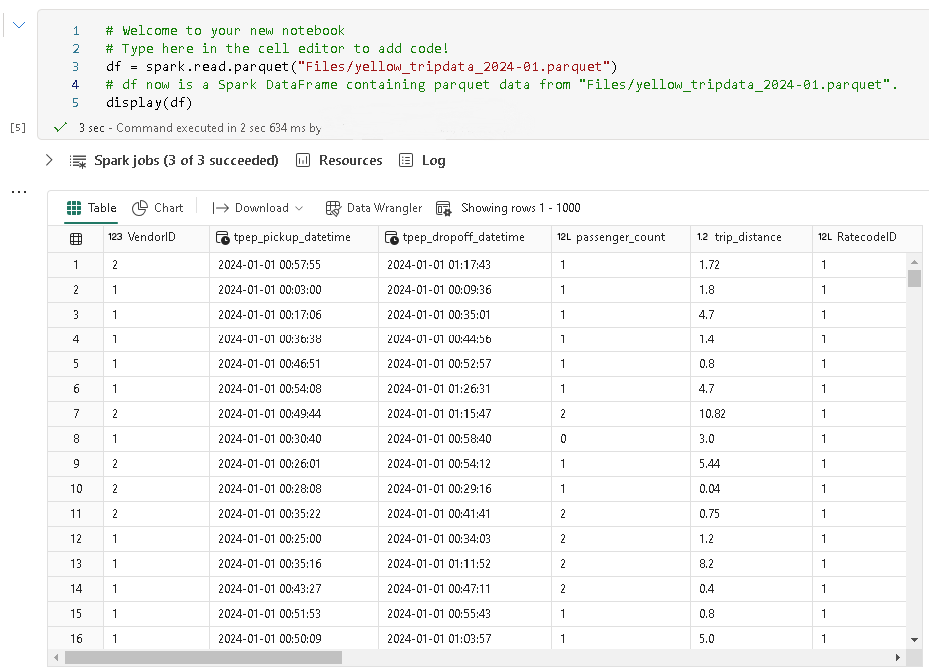
To add column for datetime, you need to import lit and current_timestamp function then adding a new column. Run the query you will see CurrentDateTime column appended to the right.
dft = df.withColumn("CurrentDateTime", lit(current_timestamp()))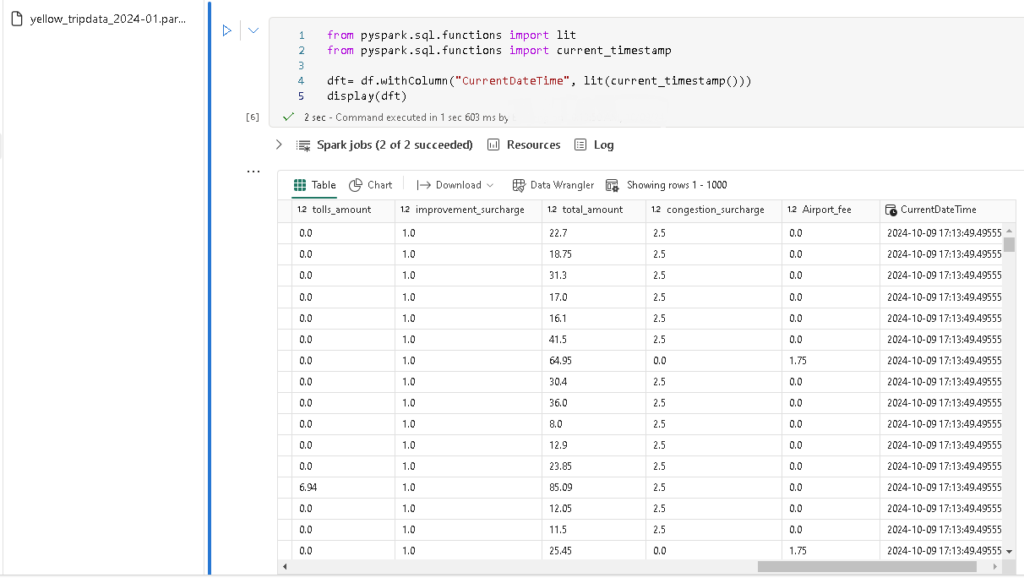
For validation purpose, you can put it in the first column by doing df.select(“columnname”, “*”), similar to how we do it in sql.
This is a very easy trick but quite useful when tracing changes, I hope you find it helpful.