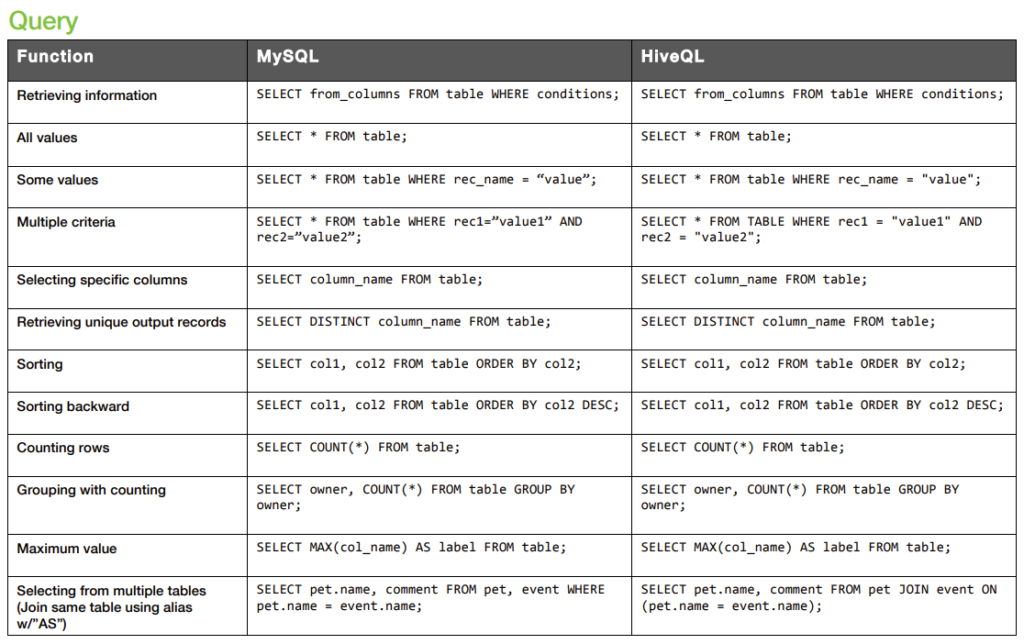
I recently encountered a project that uses HIVE table, coming from microsoft sql , mysql background, I had a little struggle with different sql syntax and behavior, thought I’d write this article on some common SQL to Hive conversions in case you are ever in similar situation.
Database:
- Creating a database: CREATE DATABASE IF NOT EXISTS db;
- Describing a database: DESCRIBE DATABASE db;
- Displaying all databases: SHOW DATABASES;
- Selecting a Database: USE db;
- Drop Database: DROP DATABASE IF EXISTS db;
Create/Load Table:
- Describing Table Details: DESCRIBE formatted table1;
- Create Internal Table: CREATE TABLE IF NOT EXISTS table1(col1 string, col2 array, col3 string, col4 int) row format delimited fields terminated by ‘,’ collection items terminated by ‘:’ lines terminated by ‘\n’ stored as parquet location ‘/user/rahul/table1’
- Create External Table: CREATE external TABLE IF NOT EXISTS table1(col1 string, col2 array, col3 string, col4 int) row format delimited fields terminated by ‘,’ collection items terminated by ‘:’ lines terminated by ‘\n’ stored as parquet location ‘/user/rahul/table1’
- Load Table From HDFS: load data inpath ‘hdfs://user/rahul/’ into table table1
- Load Table From Local FS: load data local inpath ‘/users/rahul/Desktop/file.txt’ into table table1
Alter/Drop Table:
- Alter table: ALTER TABLE employee RENAME emp;
- Alter table and add column: ALTER TABLE employee ADD COLUMNS(dept STRING COMMENT ‘Department name’)
- Drop table: DROP TABLE IF EXISTS Employee;
- Create view: CREATE VIEW emp_30000 as SELECT * FROM emp WHERE salary > 30000;
Supported Hive features
Spark SQL supports the vast majority of Hive features, such as:
- Hive query statements, including:
- SELECT
- GROUP BY
- ORDER BY
- CLUSTER BY
- SORT BY
- All Hive expressions, including:
- Relational expressions (
=,⇔,==,<>,<,>,>=,<=, etc) - Arithmetic expressions (
+,-,*,/,%, etc) - Logical expressions (AND, &&, OR, ||, etc)
- Complex type constructors
- Mathematical expressions (sign, ln, cos, etc)
- String expressions (instr, length, printf, etc)
- Relational expressions (
- User defined functions (UDF)
- User defined aggregation functions (UDAF)
- User defined serialization formats (SerDes)
- Window functions
- Joins
- JOIN
- {LEFT|RIGHT|FULL} OUTER JOIN
- LEFT SEMI JOIN
- CROSS JOIN
- Unions
- Sub-queries
- SELECT col FROM ( SELECT a + b AS col from t1) t2
- Sampling
- Explain
- Partitioned tables including dynamic partition insertion
- View
- Vast majority of DDL statements, including:
- CREATE TABLE
- CREATE TABLE AS SELECT
- ALTER TABLE
- Most Hive data types, including:
- TINYINT
- SMALLINT
- INT
- BIGINT
- BOOLEAN
- FLOAT
- DOUBLE
- STRING
- BINARY
- TIMESTAMP
- DATE
- ARRAY<>
- MAP<>
- STRUCT<>