
As data grows larger and more complex, optimizing for performance and scalability becomes essential. Partitioning is one of the most powerful strategies for managing big datasets efficiently. If you’ve come across a column like p_date in an SQL query, it often signals the use of table partitioning. But what does that mean, and how is it different from traditional databases?
What is Partitioning in a Database?
Partitioning divides a large table into smaller, more manageable units called partitions, each holding a subset of the table’s data. The full table still appears unified to users and applications, but internally, each partition can be stored and accessed separately.
Types of Partitioning
- Range Partitioning: Based on a range of values (e.g., date ranges)
- List Partitioning: Based on predefined categories (e.g., countries, regions)
- Hash Partitioning: Based on a hash of column values for even distribution
- Composite Partitioning: Combines two strategies (e.g., range + hash)
What Does p_date Mean in SQL Queries?
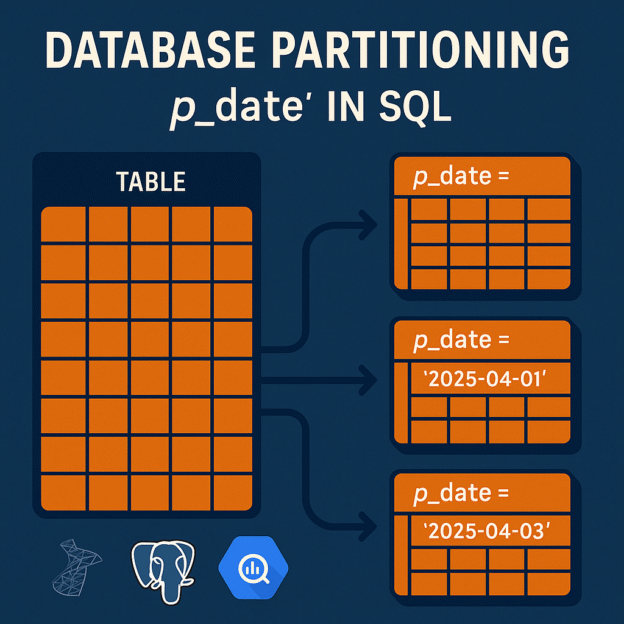
p_date is often short for partition date, used in partitioned tables to indicate which partition the row belongs to.
SELECT * FROM orders WHERE p_date = '2025-04-01';This query will scan only the partition for that date, improving speed and lowering compute cost.
Databases That Use Partitioning
Partitioning is supported in both data warehouse platforms and traditional RDBMS—but with different implementation styles:
| Database Type | Partition Support |
|---|---|
| Hive / Presto / Trino | Partitioned via file system (e.g., HDFS) using partition keys like p_date |
| BigQuery | Native partitioning by ingestion or column (e.g., _PARTITIONTIME) |
| Amazon Redshift | Supports distribution and sort keys; partitions can be mimicked via date filtering |
| Snowflake | Automatic micro-partitions; partition pruning happens under the hood |
| SQL Server | Uses PARTITION FUNCTION and PARTITION SCHEME to define partitions |
| Oracle | Supports explicit table partitioning (PARTITION BY RANGE, etc.) |
| PostgreSQL | Declarative table partitioning since version 10 |
| MySQL | Supports range, list, hash partitioning via PARTITION BY clause |
How Partitioned Databases Differ from Traditional Ones
Here’s a comparison of partitioned vs. non-partitioned (traditional) databases:
| Feature | Partitioned Table | Traditional Table |
|---|---|---|
| Data Storage | Divided across partitions based on key (e.g., date) | Stored in one large table/file |
| Query Efficiency | High if partition pruning is used | Slower on large datasets, full table scan needed |
| Maintenance | Easier to drop or load data by partition | Requires full-table operations |
| Cost (Cloud Platforms) | Lower (e.g., BigQuery scans less data) | Higher (full table scan for every query) |
| Scalability | Horizontally scalable for massive data | Limited performance beyond a certain size |
| Backup & Archival | Individual partitions can be archived or purged | Archival often done on entire table |
Key Concept: Partition Pruning
In partitioned systems, if your query includes a filter on the partition key (like p_date), the query engine skips scanning irrelevant partitions. This is called partition pruning, and it’s the core performance advantage of partitioned tables.
Best Practices
- Use
WHERE p_date = '...'instead of wrapping it in functions (e.g.,DATE(p_date)) - Choose partition keys that match common query filters (e.g., time-based keys)
- Avoid too many partitions (e.g., one per second) to reduce metadata overhead
Conclusion
Partitioning transforms the way databases manage, store, and query large datasets. Whether it’s a modern data warehouse like BigQuery or an enterprise RDBMS like SQL Server, partitioning allows systems to scale efficiently while keeping queries fast and costs low. Understanding the role of p_date and how partitioning differs from traditional models can significantly improve your data engineering strategy.