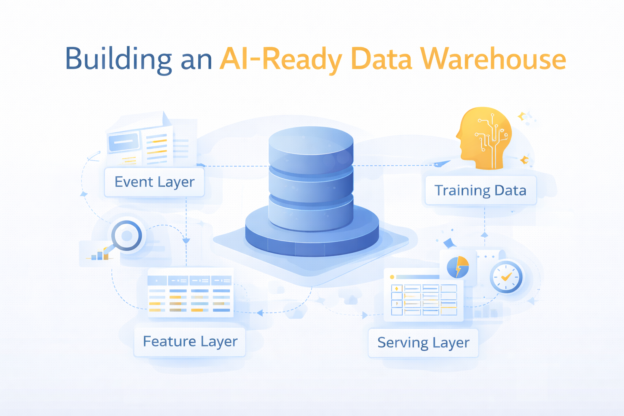
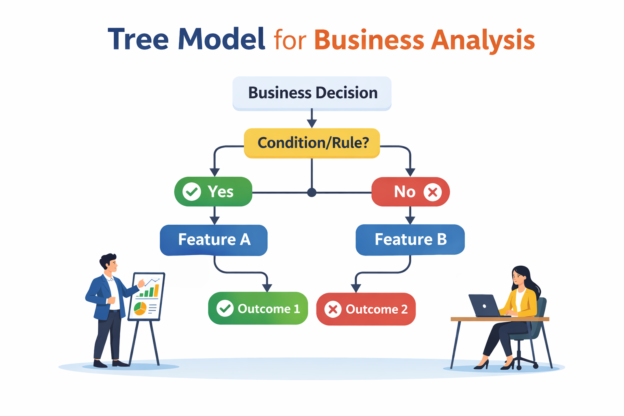
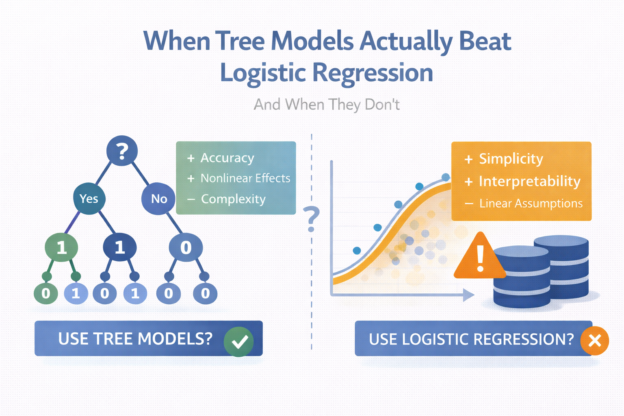
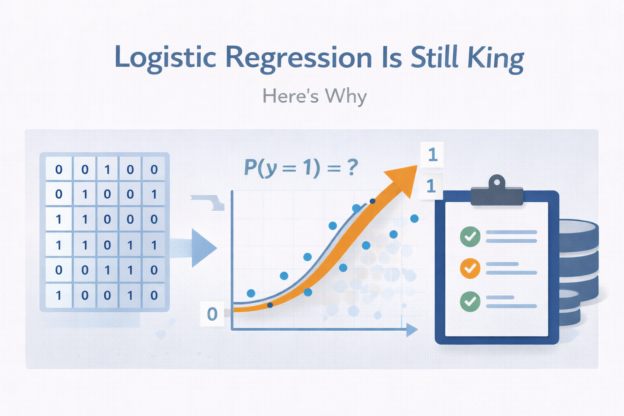
Over the past two years, artificial intelligence has rapidly entered the world of data and analytics. Large language models can now write SQL, explain trends, generate dashboards, and summarize reports in seconds. Because of this, a common question is starting to appear in data teams and executive meetings:
Continue reading