
Most companies don’t fail at AI because of models. They fail because of data.
More specifically:
They try to run AI workloads on top of a data warehouse that was never designed for it.
Traditional data warehouses are optimized for:
- dashboards
- reporting
- business metrics
AI systems require something different:
- behavioral data
- time-aware pipelines
- reproducible datasets
- feature consistency across training and inference
This article lays out a clear, practical framework for building an AI-ready data warehouse, grounded in real systems and real trade-offs.
1. The Core Shift: From Reporting Systems to Decision Systems
The cleanest way to understand the transition is this:
| BI Warehouse | AI-Ready Warehouse |
|---|---|
| Describes what happened | Enables what will happen |
| Aggregates data | Preserves behavior |
| Human-readable metrics | Machine-ready features |
| Batch reporting | Continuous signals |
Example
BI mindset:
“What is our 30-day retention rate?”
AI mindset:
“Which users are likely to churn next week—and why?”
These are fundamentally different data problems.
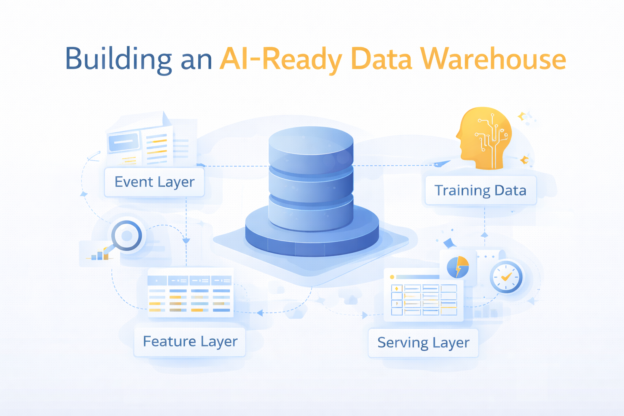
2. The Four Layers of an AI-Ready Data Warehouse
Instead of thinking in tools, think in layers.
Layer 1: Event (Raw Behavioral Data)
This is the most important—and most commonly missing.
Required structure:
user_id | event_type | event_time | attributes
Examples:
- page_view
- add_to_cart
- purchase
- login
Why It Matters
All meaningful features come from events.
Example: Churn Signal
From events:
SELECT
user_id,
MAX(event_time) AS last_activity
FROM user_events
GROUP BY user_id;
Then derive:
CURRENT_DATE - last_activity AS days_since_last_activity
Common Failure
Teams only store:
daily_active_users
monthly_active_users
Result:
- no behavioral reconstruction
- no feature engineering
Layer 2: Feature Layer (Machine-Ready Data)
This is where BI systems usually fall short.
Example: Feature Table
SELECT
user_id,
COUNT(*) FILTER (WHERE event_time >= CURRENT_DATE - INTERVAL '7 days') AS events_7d,
COUNT(*) FILTER (WHERE event_time BETWEEN CURRENT_DATE - INTERVAL '14 days' AND CURRENT_DATE - INTERVAL '7 days') AS events_8_14d,
MAX(event_time) AS last_event_time,
AVG(order_value) AS avg_order_value
FROM user_events
LEFT JOIN orders USING(user_id)
GROUP BY user_id;
Why This Matters
This enables:
- trend detection
- recency effects
- behavior modeling
Key Insight
BI compresses data.
AI expands it into signals.
Layer 3: Training Data (Time-Correct Snapshots)
This is where many teams silently break models.
The Problem: Data Leakage
Bad example:
SELECT
user_id,
total_orders_30d,
churn_flag
FROM users;
If total_orders_30d includes future data → model is invalid.
Correct Approach
SELECT
user_id,
COUNT(*) AS orders_before_cutoff
FROM orders
WHERE order_date < '2024-01-01'
GROUP BY user_id;
Add Snapshot Versioning
user_features_2024_01_01
user_features_2024_02_01
Why This Matters
- reproducibility
- debugging
- consistent evaluation
Layer 4: Serving Layer (Real-Time / Near Real-Time)
Models don’t live in notebooks.
They live in systems.
Example: Fraud Detection
Needs:
- last 5 min transaction count
- device change flag
- location anomaly
Challenge
Warehouse updates daily → too slow.
Solution
Hybrid system:
- batch features (warehouse)
- real-time features (streaming / cache)
Key Insight
AI systems require both historical depth and real-time freshness.
3. End-to-End Use Cases
Let’s connect all layers with real systems.
Case 1: Churn Prediction System
Step 1: Event Layer
user_id | event_type | event_time
Step 2: Feature Layer
- events_7d
- events_30d
- days_since_last_activity
- avg_order_value
Step 3: Training Dataset
Snapshot:
user_features_2024_01_01
+ churn_flag (next 30 days)
Step 4: Model
Predict churn probability.
Step 5: Serving
Daily batch scoring:
- flag high-risk users
- trigger retention campaigns
Key Insight
This entire pipeline depends on time-aware feature construction.
Case 2: Fraud Detection
Requirements
- millisecond-level decisions
- behavioral anomaly detection
Data System
Event stream:
transaction_id | user_id | timestamp | amount | device
Features:
- transactions_last_5min
- avg_amount
- device_switch
Architecture
- real-time ingestion
- feature computation
- model scoring
Key Insight
Fraud detection cannot be built on batch-only warehouses.
Case 3: Recommendation System
Problem
Recommend products based on behavior.
Data Required
user_id | product_id | interaction | timestamp
Features
- recent_views
- purchase_history
- category affinity
Model
Predict probability of interaction.
Outcome
- personalized recommendations
- increased conversion
Key Insight
Aggregates (top products) are not enough.
Behavior sequences matter.
Case 4: LLM + RAG System
Problem
LLM needs context.
Data Layer
doc_id | content | embedding | metadata
Additional Logs
query | retrieved_docs | response | feedback
Why It Matters
- improves retrieval
- enables evaluation
- supports iteration
Key Insight
LLM quality depends heavily on data retrieval quality.
4. Critical Design Principles
4.1 Time Is a First-Class Dimension
Every feature must answer:
“What did we know at that moment?”
4.2 Features Must Be Reusable
Avoid:
- rebuilding logic per model
Build:
- shared feature definitions
4.3 Training = Serving Consistency
Same logic must apply:
- offline (training)
- online (prediction)
Otherwise:
- model performance collapses
4.4 Data Quality Is Non-Negotiable
Monitor:
- null rates
- distribution shifts
- schema changes
5. Common Failure Modes
Over-Aggregation
Too many summary tables → no flexibility.
No Snapshotting
Cannot reproduce results.
Weak Identity Resolution
User IDs don’t align across systems.
Ignoring Real-Time Needs
Batch-only systems → limited AI capability.
6. A Practical Build Path
Phase 1: Fix Data Foundations
- event tracking
- clean schemas
- consistent IDs
Phase 2: Build Feature Layer
- user-level features
- time-aware pipelines
Phase 3: Add Versioning
- snapshot datasets
- reproducible training
Phase 4: Support Real-Time Use Cases
- streaming features
- online scoring
Phase 5: Add Monitoring
- feature drift
- model performance
Final Thoughts
An AI-ready data warehouse is not:
- a new tool
- a buzzword
- a complete rebuild
It is a disciplined evolution of your data system.
The real shift is:
From describing the business
→ to enabling decisions within the business
And that requires:
- better data structure
- stronger pipelines
- clearer definitions
- system-level thinking
Because in the end:
The hardest part of AI is not the model.
It’s the data system that supports it.
Discover more from Daily BI Talks
Subscribe to get the latest posts sent to your email.